GPT4SGG: Synthesizing Scene Graphs from Holistic and Region-specific Narratives
Abstract
Training Scene Graph Generation (SGG) models with natural language captions has become increasingly popular due to the abundant, cost-effective,
and open-world generalization supervision signals that natural language offers.
However, such unstructured caption data and its processing pose significant challenges in learning accurate and comprehensive scene graphs.
The challenges can be summarized as three aspects:
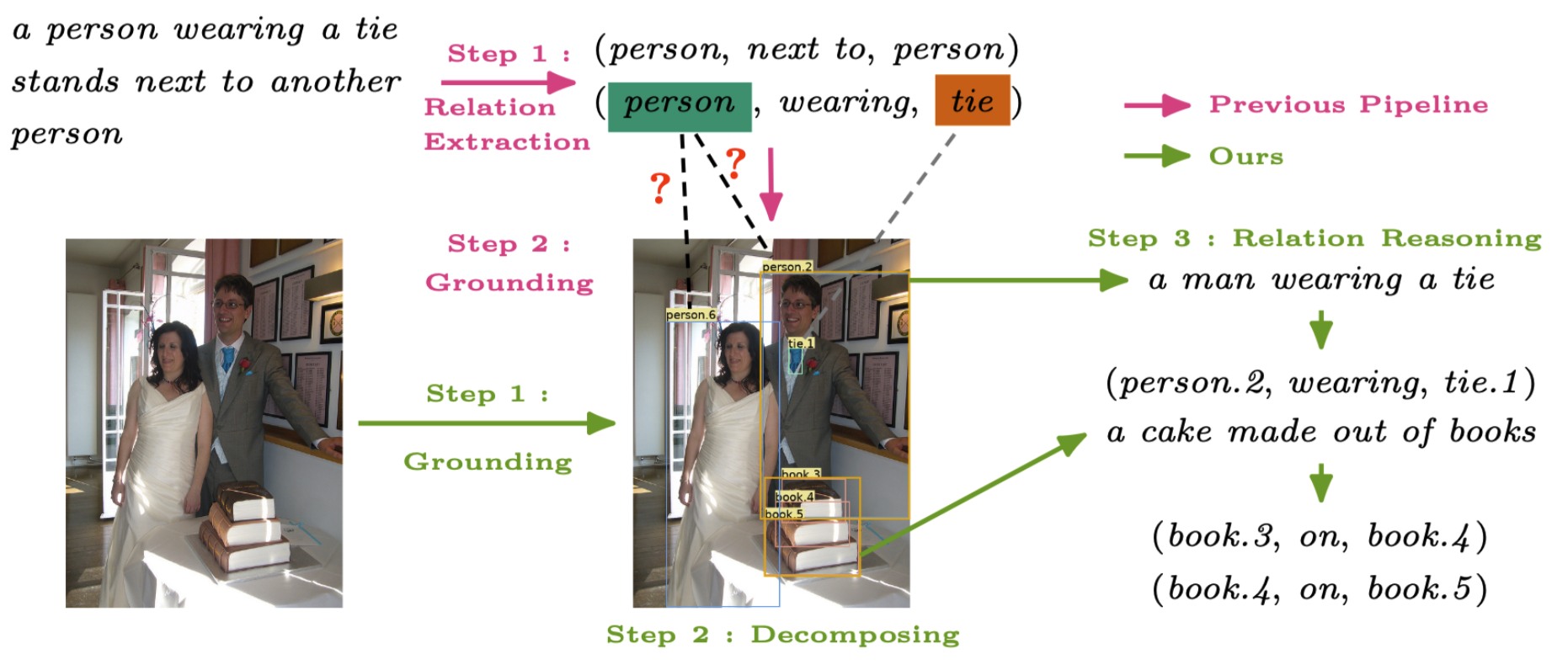
1) traditional scene graph parsers based on linguistic representation often fail to extract meaningful relationship triplets from caption data.
2) grounding unlocalized objects of parsed triplets will meet ambiguity issues in visual-language alignment.
3) caption data typically are sparse and exhibit bias to partial observations of image content.
Aiming to address these problems, we propose a divide-and-conquer strategy with a novel framework
named GPT4SGG, to obtain more accurate and comprehensive scene graph signals.
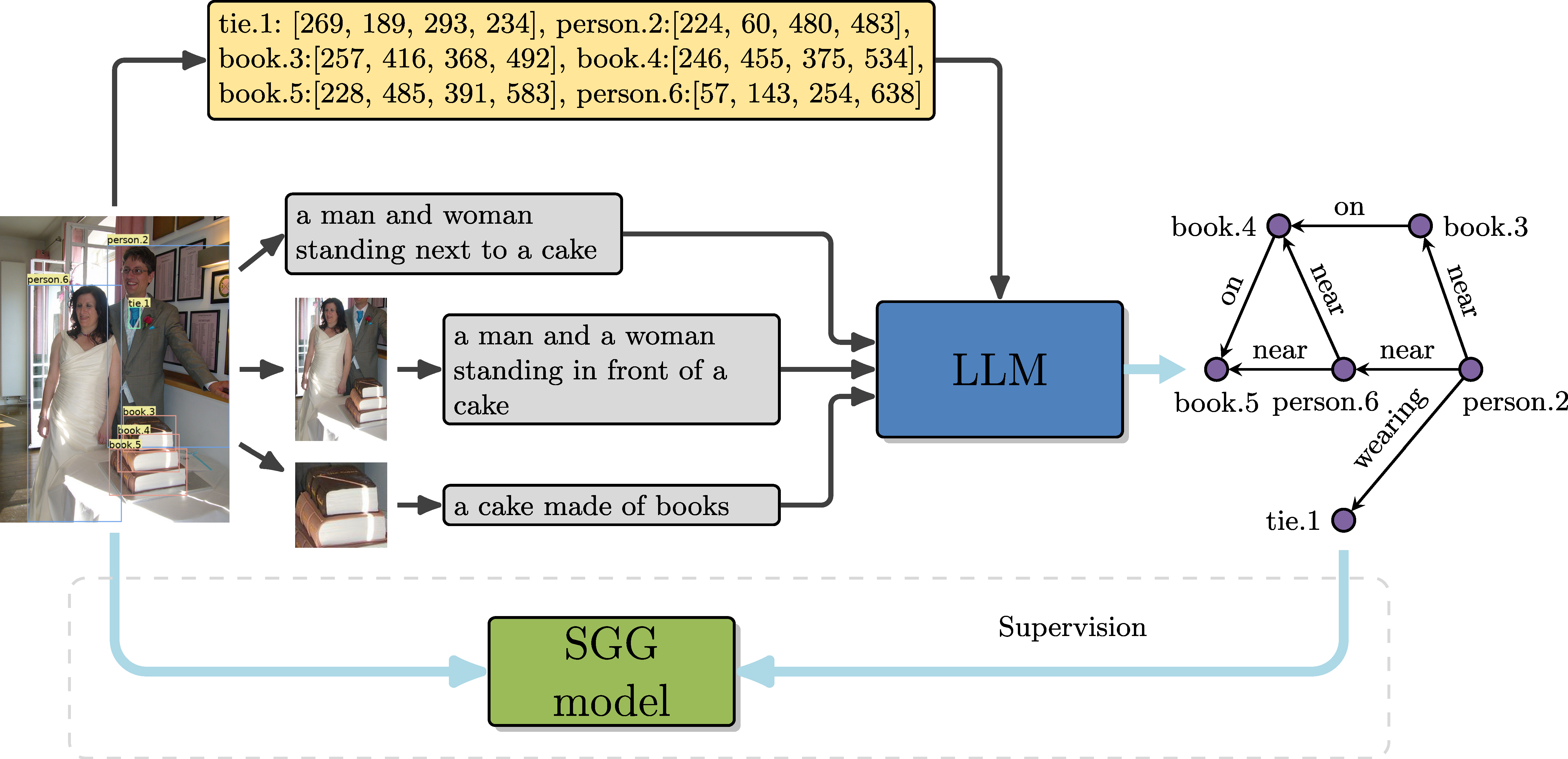
This framework decomposes a complex scene into a bunch of simple regions,
resulting in a set of region-specific narratives. With these region-specific narratives (partial observations) and a holistic narrative (global observation) for an image,
a large language model (LLM) performs the relationship reasoning to synthesize
an accurate and comprehensive scene graph.
Task-specific (SGG-aware) Prompt: synthesize scene graphs based on the textual input for image data.
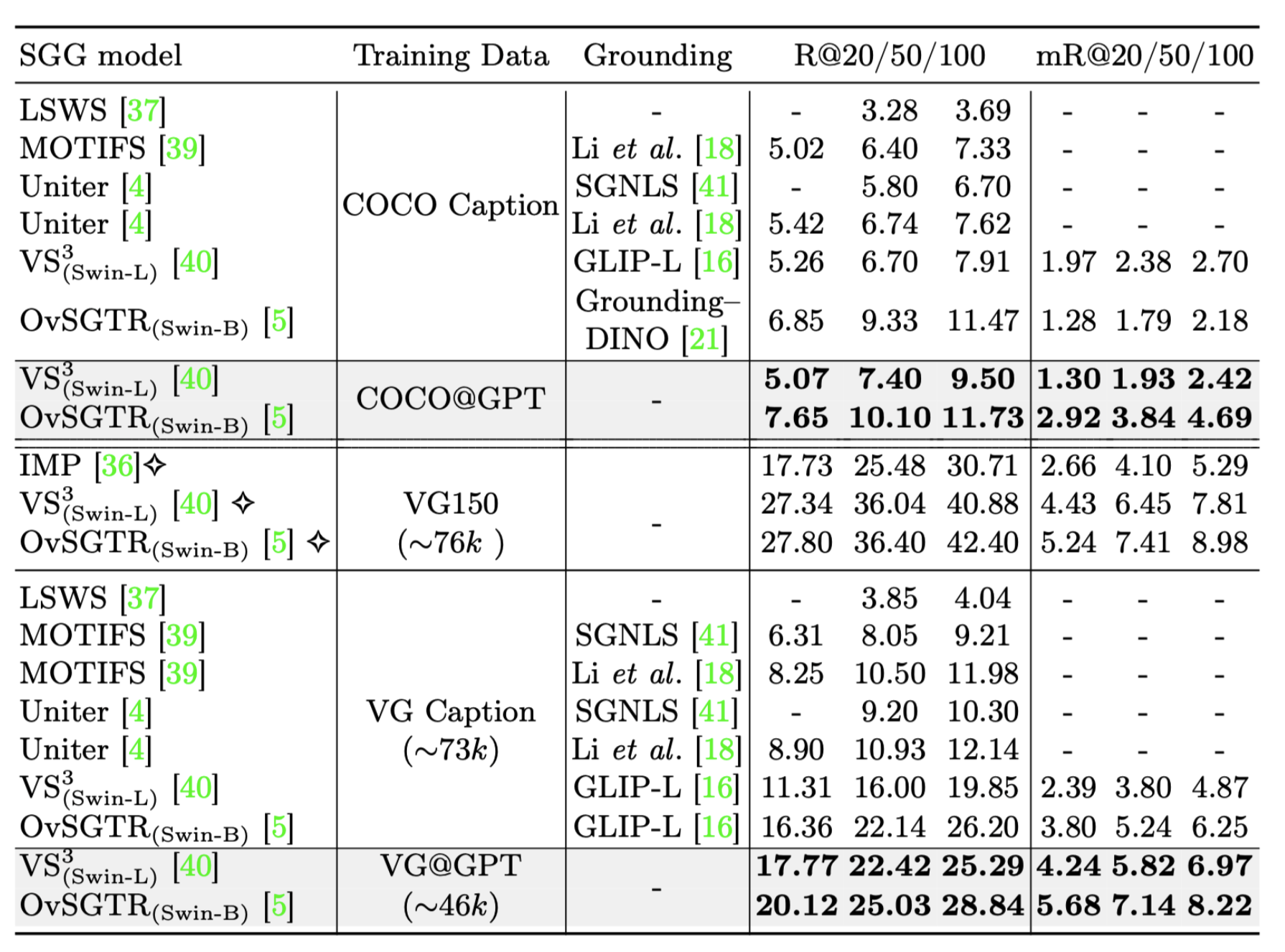
Comparison with state-of-the-arts on VG150 test set, diamond symbol marks fully supervised methods
Example of GPT4SGG
Samples of COCO-SG@GPT
BibTeX
Please cite GPT4SGG in your publications if it helps your research:
@misc{chen2023gpt4sgg,
title={GPT4SGG: Synthesizing Scene Graphs from Holistic and Region Narratives},
author={Zuyao Chen and Jinlin Wu and Zhen Lei and Changwen Chen},
year={2023},
eprint={2312.04314},
archivePrefix={arXiv},
primaryClass={cs.CV}
}